Deep Dive into the MACE Architecture¶
![]()
In this tutorial, you will do a dive into the MACE code, which is a highly accurate and efficient MLIP. If you would like to understand this method in more detail, you can find the original method paper. MACE is a Message Passing Neural Network (MPNNs) Interatomic Potential that forms equivariant many body messages.
MACE was developed by unifying the Atomic Cluster Expansion (ACE) approach with the equivariant MPNNs. The mathematical formalism which unifies these methods is explained in the accompaning paper. Another useful reference showcases the methods performance on published benchmark datasets aswell as updated set of equations that we will follow in this notebook. The code implementation is publically available and here you can find the accompaning documentation.
The tutorial was developed by Will Baldwin and is based on a ‘developer tutorial’ from Ilyes Batatia at University of Cambridge
There isn’t much ‘computing’ to be done for this notebook - the idea is to expose some of the inner functions and give you the option ot see whats going on by fiddling with the internals.
Setup(optional)¶
The next cell needs to be run only if you use google colab. Commands may work in other environments too but are not tested.
[ ]:
import locale
locale.getpreferredencoding = lambda: "UTF-8"
! pip uninstall -y torch torchvision torchaudio
! uv pip install mace-torch torch==2.5.1 torchvision data-tutorials weas_widget --system
get_ipython().kernel.do_shutdown(restart=True)
now grab the data needed for tutorial
[ ]:
from data_tutorials.data import get_data
get_data(
url="https://raw.githubusercontent.com/ccp5UK/summerschool/main/Day_11ML/figures/",
filename=["active_learning.png","embedding_layer.png","interaction_first_layer.png","interaction_layer.png","interaction_layer_second.png","iterative_training.png","mace_architecture_layers.png","mace_architecture.png","product_layer.png","readout.png","sketch.png"],
folder="figures/",
)
get_data(
url="https://raw.githubusercontent.com/ccp5UK/summerschool/main/Day_11ML/data/",
filename=["solvent_rotated.xyz"],
folder="data/",
)
MACE is a function which takes in an atomic environment and computes an energy. In some of the lectures, we discussed the steps of ‘designing features’ and ‘fitting’ seperately. In MACE, these two steps are really blended together.
This is illustrated in the figure above - most of the weights (and most of the computational effort) in a MACE model is constructing the atomic features. One you have these, the energy is a relatively simple learnable function of these features.
In this tutoral we will look inside the feature construction of MACE and examine the individual equations and blocks of code.
Schematic of MACE¶
The Figure shows a schematic of MACE. The key steps are:
The Embedding. Atomic structures are turned into an initial set of ‘features’ describing the chemical species of each node, and describing the length and orientation of each edge.
Feature Construction
2.1) Interaction: Information is pooled from neighbours
2.2) Product: the information aggregated from neighbours is raised to a power, creating many body descriptors.
2.3) Update: the previous node features are updated based on the output from the product step.
Readout. The new features are mapped to an energy.
Repeat. The process is repeated, but the informatino describing each node (node features 1) is now much richer than it was in the previous iteration (node features 0).
Default Model Parameters¶
declare some things now to keep the notebook tidy - we will come back to them later
[ ]:
import numpy as np
import torch
import torch.nn.functional
from e3nn import o3
from matplotlib import pyplot as plt
import ase.io
%matplotlib inline
from ase.visualize import view
from scipy.spatial.transform import Rotation
from mace import data, modules, tools
from mace.tools import torch_geometric
torch.set_default_dtype(torch.float64)
[ ]:
# setup some default prameters
z_table = tools.AtomicNumberTable([1, 6, 8])
atomic_energies = np.array([-1.0, -3.0, -5.0], dtype=float)
cutoff = 3
default_model_config = dict(
num_elements=3, # number of chemical elements
atomic_energies=atomic_energies, # atomic energies used for normalisation
avg_num_neighbors=8, # avg number of neighbours of the atoms, used for internal normalisation of messages
atomic_numbers=z_table.zs, # atomic numbers, used to specify chemical element embeddings of the model
r_max=cutoff, # cutoff
num_bessel=8, # number of radial features
num_polynomial_cutoff=6, # smoothness of the radial cutoff
max_ell=2, # expansion order of spherical harmonic adge attributes
num_interactions=2, # number of layers, typically 2
interaction_cls_first=modules.interaction_classes[
"RealAgnosticResidualInteractionBlock"
], # interation block of first layer
interaction_cls=modules.interaction_classes[
"RealAgnosticResidualInteractionBlock"
], # interaction block of subsequent layers
hidden_irreps=o3.Irreps("8x0e + 8x1o"), # 8: number of embedding channels, 0e, 1o is specifying which equivariant messages to use. Here up to L_max=1
correlation=3, # correlation order of the messages (body order - 1)
MLP_irreps=o3.Irreps("16x0e"), # number of hidden dimensions of last layer readout MLP
gate=torch.nn.functional.silu, # nonlinearity used in last layer readout MLP
)
default_model = modules.MACE(**default_model_config)
Representing Spherical Tensors: Ylm’s¶
Within many popular MLIP architectures, including MACE, descriptors are represented as ‘spherical tensors’.
To explain spherical tensors we first need to state that the spherical harmoincs ‘transform’ in a special way when their argument is rotated. This means that if you take a vector \(\boldsymbol{\hat{r}}\) and rotate it by some matrix, \(\boldsymbol{\hat{r}} \rightarrow R\boldsymbol{\hat{r}}\), the value of the spherical harmonic \(Y^{m}_{l} (\boldsymbol{\hat{r}})\) will also change. You don’t need to know the maths of how the \(Y_{m}^l\) transforms today, but in short this is the result:
In which \(D(R)\) is a unitary matrix called a Wiger D-matrix. You can find more info here.
The embeddings in MACE contain a function to compute the spherical harmonics. Lets quickly demonstrate how \(Y^{m}_{l}\) changes as \(\boldsymbol{\hat{r}}\) is rotated.
[ ]:
# a function for Ylms where we evaluate for l=0,1,2.
spherical_harmonics = o3.SphericalHarmonics([0,1,2], True)
# evaulate spherical harmonics on a vector
vector = torch.tensor([1.0, 0.2, 0.75])
print(spherical_harmonics(vector))
Why is the array 9 elements long? We calculated the \(l=0,1,2\) for all valid \(m's\), and stored them in this format:
Which has 9 elements in total. Generally, this is how most arrays are stored in MACE. The final dimesion of the array combines the \(l\) and \(m\) indicices, and concatenates the values like this.
How do these transform under rotations? We can simply rotate the vector and get an idea for what happens by plotting the result:
[ ]:
# make a list of rotated versions of the vector
rotated_vectors = []
vector = np.array([1.0, 0.2, 0.75])
N=360
for i in range(N):
rotation_matrix = Rotation.from_rotvec(i * 2*np.pi * np.array([0, 0.7071, 0.7071])/360).as_matrix() # rotate around the vector [0, 0.7071, 0.7071]
rotated_vectors.append(rotation_matrix @ vector)
# convert to torch tensor
rotated_vectors = torch.tensor(rotated_vectors, dtype=torch.float32)
# compute the spherical harmonics for each vector
spherical_harmonic_values = spherical_harmonics(rotated_vectors)
print('shape of Y_lms array is ', spherical_harmonic_values.shape)
# plot
labels = [[f'l={l}, m={m}' for m in range(-l,l+1)] for l in range(3)]
labels = [x for xs in labels for x in xs] # flatten
plt.plot(spherical_harmonic_values.numpy(), label=labels)
plt.legend()
plt.xlabel('rotation angle')
plt.ylabel('spherical harmonic value')
plt.show()
The key points to note are that the \(l=0\) component is constant - it does not change when the vector is rotated. The other components do change, and as \(l\) increases the frequency of the features increases.
Getting Invariant Quantities with e3nn¶
Enevtually we want to make a model where the output is invariant to rotations. To do this, we could just take the \(l=0\) piece of the spherical harmonics, but doing this doesn’t give us much information.
For example: Lets take a pair of vectors, get the spherical harmonics for both.
[ ]:
np.random.seed(0)
vector1 = np.random.randn(3)
vector1 = vector1 / np.linalg.norm(vector1)
vector2 = np.random.randn(3)
vector2 = vector2 / np.linalg.norm(vector2)
spherical_harmonics_1 = spherical_harmonics(torch.tensor(vector1))
spherical_harmonics_2 = spherical_harmonics(torch.tensor(vector2))
print('l=0 component for vector 1:', spherical_harmonics_1[0])
print('l=0 component for vector 2:', spherical_harmonics_2[0])
This isn’t very useful, because the \(l=0\) piece doesn’t contain any angular information for either vector, so we have no way to know, for instance, the angle between them.
You can test this by changing one or both of the vectors (via the numpy seed). The \(l=0\) piece won’t change.
How do we get Invariants which describe angular information?¶
To get a more descriptive invariant quantity, we need to do some operations on the spherical harmoincs. We care about how spherical harmonics change when you rotate the input, because its easy to keep track of how rotation affects things. This means that its easy to get back to an invariant quantity when we need to. In MACE, and many other MLIPs, this maths is done by a package called e3nn.
e3nn provides functions which perform operations on spherical tensors (things with elements like \([Y_{0}^0, Y_{1}^{-1}, Y_{1}^0, ...]\)), while keeping track of the rotations. One example operation is a tensor product, which takes two arrays, \(A_{lm}\) and \(B_{lm}\), and multiplies them to give \(C_{lm}\):
The key is that \(C\) is still indexed by \(l\) and \(m\), so if we look at the \(l=0\) piece, it will still be invariant! This means we can do a load of operations to combine spherical harmonics, and then create invariant descrpitors which know about things like angles ebtween vectors.
We can demonstrate this by the two vectors above, doing the tensor product of them, and keeping all the outputs which are invariant to rotations.
[ ]:
# set up a tensor product.
# This does the product of two l=0,1,2 arrays, and maps the result to three l=0 values.
tensor_product = o3.FullyConnectedTensorProduct(
irreps_in1=o3.Irreps("1x0e + 1x1o + 1x2e"),
irreps_in2=o3.Irreps("1x0e + 1x1o + 1x2e"),
irreps_out=o3.Irreps("3x0e"),
internal_weights=False
)
print(tensor_product)
tensor_product.visualize()
The diagram shows schematically how the tensor product is combining the elements of the inputs to make the output.
[ ]:
# product the arrays
product = tensor_product(
spherical_harmonics_1.unsqueeze(0),
spherical_harmonics_2.unsqueeze(0),
weight=torch.arange(1,10,1) # the product has weights which can be trained - for now I have fixed them
)
print('invariant outputs:', product)
Now we have three outputs, and they have the property that they are invariant to rotations of the entire structure (i.e. rotating oth vectors) but then still change when the angle between the vectors changes.
We can demonstrate this:
[ ]:
angle = 77.7 # degrees
rotation_matrix = Rotation.from_rotvec(angle * 2*np.pi * np.array([0, 0.7071, 0.7071])/360).as_matrix()
rotated_vec1 = rotation_matrix @ vector1
rotated_vec2 = rotation_matrix @ vector2
# get the spherical harmpnics
spherical_harmonics_1 = spherical_harmonics(torch.from_numpy(rotated_vec1))
spherical_harmonics_2 = spherical_harmonics(torch.from_numpy(rotated_vec2))
product = tensor_product(
spherical_harmonics_1.unsqueeze(0),
spherical_harmonics_2.unsqueeze(0),
weight=torch.arange(1,10,1) # the product has weights which can be trained - for now I have fixed them
)
print('invariant outputs:', product)
You can see that the values are the same as before the rotation, but if you go back and change the seed used for creating the two vectors, they will be different. This meas that we have have made invariant quantities which can tell two pairs of unit vectors apart.
These kind of operations are what MACE is built on.
MACE Feature Construction¶
We can now go through some key parts of the feature construction and look at the internal variables. The schematic at the top of the document has a full overview, and the key bits will be repeated.
0. Data Prep¶
The first step in MACE is to take the atomic structure and represent it as a list of atoms and ‘edges’. An edge is simply a connection between two atoms. The cutoff radius of the MACE layer determines which atoms are connected by an edge.
Below we load a list of molecule, and show how the atoms and edges are stored.
[ ]:
from weas_widget import WeasWidget
from IPython.display import display
viewer = WeasWidget()
single_molecule = ase.io.read('data/solvent_rotated.xyz', index='0')
viewer.from_ase(single_molecule)
viewer.avr.model_style = 0
viewer.avr.show_hydrogen_bonds = True
display(viewer)
Rcut = 3.0 # cutoff radius
z_table = tools.AtomicNumberTable([1, 6, 8])
config = data.Configuration(
atomic_numbers=single_molecule.numbers,
positions=single_molecule.positions,
properties={},
property_weights={}
)
# we handle configurations using the AtomicData class
batch = data.AtomicData.from_config(config, z_table=z_table, cutoff=Rcut)
print("positions:", batch.positions)
print("node_attrs:", batch.node_attrs)
print("edge_index:", batch.edge_index)
The node_attrs describe the species. [1,0,0] means the first kind of element, [0,1,0] means the second kind, and so on.
In this case we told MACE to work with Hydrogen, Carbon and Oxygen with the line z_table = ....
The ‘edges’ are stored by a list of ‘senders’ and ‘receievers’, which represent the start and end point of each edge.
We can now compute the lengths and directions of each edge:
[ ]:
vectors, lengths = modules.utils.get_edge_vectors_and_lengths(
positions=batch["positions"],
edge_index=batch["edge_index"],
shifts=batch["shifts"],
)
print(f'there are {batch.positions.shape[0]} nodes and {len(lengths)} edges')
print(f'lengths is shape {lengths.shape}')
print(f'vectors is shape {vectors.shape}')
1. Embeddings¶
We now take this information and make the initial inputs to the MACE model. This is called the embedding.
Key concept: MACE ‘channels’¶
The equation for the initial node features looks like this:
Take the exmaple where all atoms are either hydrogen or carbon. If atom \(i\) is hydrogen, the its initial node features are just \(W_{k0}\). If atom \(n\) is carbon it will get initial features \(W_{k1}\). This means that each atom is given a vector of length \(K\), based on its chemical species.
In mace, the range of k is referred to as the number of 'channels'. This is the fundamental 'size' of the descriptor the figure at the top of the notebook sort of shows this.
This operation of giving each atom a length-K vector depending on its species is called the node ‘embedding’.
We also ‘embed’ the lengths and directions of the edges. The lengths of the edges are mapped through a set of 8 bessel functions, and for the dircetion of the edge we just calculate the spherical harmoincs.
[ ]:
# set up a mace model to get all of the blocks in one place:
model = modules.MACE(**default_model_config)
initial_node_features = model.node_embedding(batch.node_attrs)
edge_features = model.radial_embedding(lengths, batch["node_attrs"], batch["edge_index"], z_table)
edge_attributes = model.spherical_harmonics(vectors)
print('initial_node_features is (num_atoms, num_channels):', initial_node_features.shape)
print('edge_features is (num_edge, num_bessel_func):', edge_features.shape)
print('edge_attributes is (num_edge, dimension of spherical harmonics):', edge_attributes.shape)
print(
'\nInitial node features. Note that they are the same for each chemical element\n',
initial_node_features
)
[ ]:
# we can plot what the 'edge features' look like as a function of edge length:
dists = torch.tensor(np.linspace(0.1, cutoff, 100), dtype=torch.get_default_dtype()).unsqueeze(-1)
radials = model.radial_embedding(dists, batch["node_attrs"], batch["edge_index"], z_table)
for i in range(radials.shape[1]):
plt.plot(dists, radials[:, i], label=f'edge feat {i}')
# Add title, labels, and legend
plt.title("Edge features")
plt.xlabel("distance / A")
plt.ylabel("Value")
plt.legend()
# Display the plot
plt.show()
The parameter max_ell in the mace config (top of file) controls the maximum \(l\) in the spherical harmonics, and hence the dimension of the edge_attributes.
The intial node features are invariant, and depend only on the speices. You can check this by printing them and comparing to batch.node_attrs.
The edge features are invariant because they only depend on length, and the edge attributes are of course spherical harmonics, and change as things rotate.
2. Interaction¶
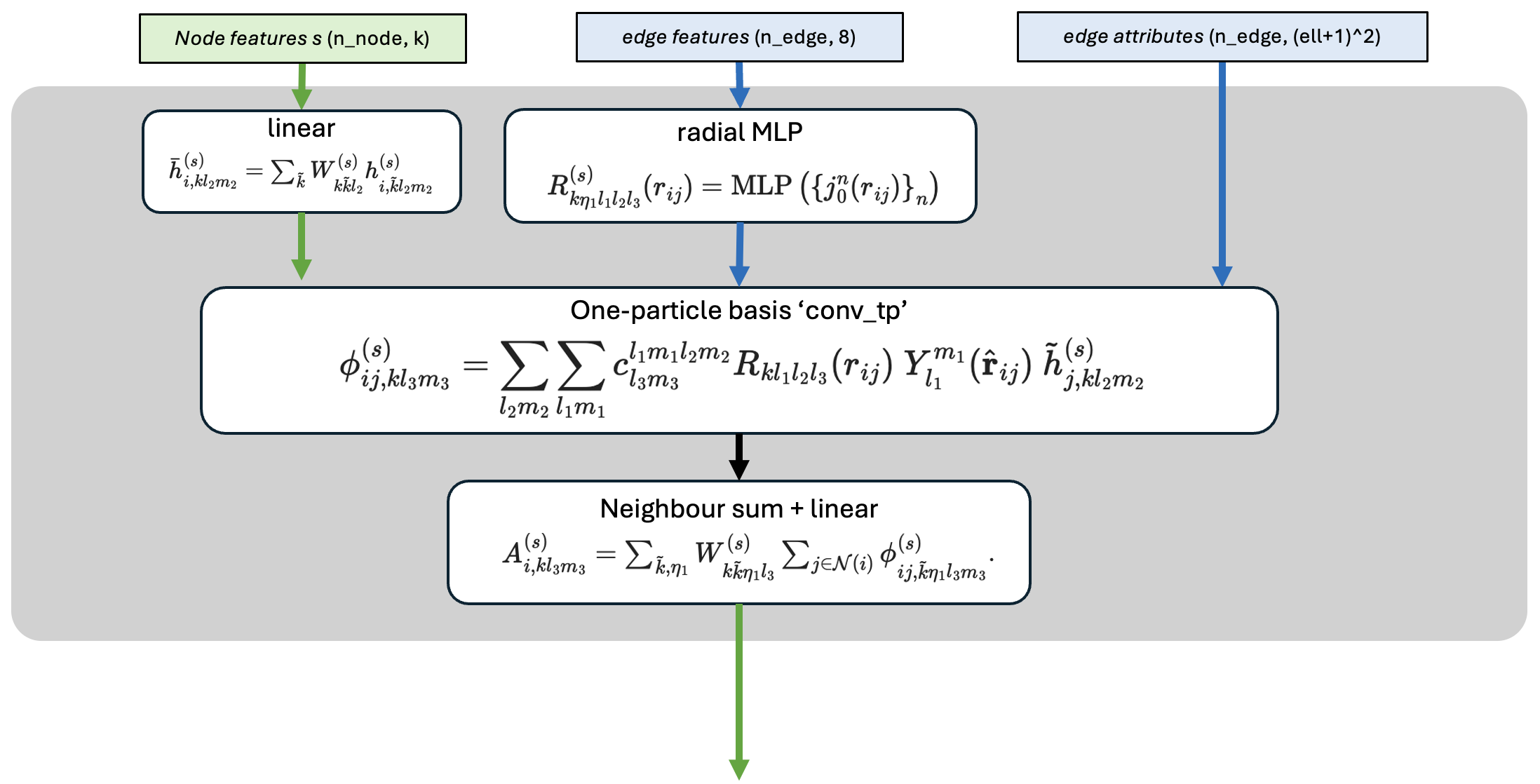
Having created the intial features, the fun begins. The interaction block is tasked with pooling information over neighbours while tracking the properties of all arrays with \((l,m)\) indices. The output is a set of atomic features which contain information about the neighbours but are still 2-body.
The figure below shows all the equations of the interaction which is used in the first layer. In the second layer of mace, the interaction step is significantly more complex - the end of this notebook discusses this if you are interested.
The first layer of MACE is actually very similar to the simpler, and related, ACE model. We won’t go through the internals of the interaction, but its at the end of the notebook if you are interested.
[ ]:
Interaction = model.interactions[0]
intermediate_node_features, sc = Interaction(
node_feats=initial_node_features,
node_attrs=batch.node_attrs,
edge_feats=edge_features,
edge_attrs=edge_attributes,
edge_index=batch.edge_index,
)
print("the output of the interaction is (num_atoms, channels, dim. spherical harmonics):", intermediate_node_features.shape)
One important part of the interaction is how the edge_attrs (the bessel function values) enter.
The bessel function values are mapped through a multilayer perceptron (‘radial MLP’) to make a large number of learnable functions of edge length. The output is sometimes called a ‘learnable raidal basis’ \(R_{kl}(r_{ij})\) - one radial function for each \((k,l)\) combination.
These learnable functions are then combined with the spherical harmonics of the \(j\rightarrow i\) edge, and the initial node features of the neighbouring atom (\(j\)). The result is that \(\phi_{ij,klm}(\mathbf{r}_{ij})\) is quite a rich set of descriptors of the \(j\)’th neighbour atom.
We can plot some of these radial functions to see how kind of shapes they have.
[ ]:
# visulaise what the radial MLP does
dists = torch.tensor(np.linspace(0.1, cutoff, 100), dtype=torch.get_default_dtype()).unsqueeze(-1)
# first do radial embedding again
edge_feats_scan = model.radial_embedding(dists, batch["node_attrs"], batch["edge_index"], model.atomic_numbers)
# put the edge feats into the radial MLP
tp_weights_scan = model.interactions[0].conv_tp_weights(edge_feats_scan).detach().numpy()
print('the output of the radial MLP is (num_dists, num_weights):', tp_weights_scan.shape)
# plot the outputs
num_basis_to_print = 5
for i in range(num_basis_to_print):
plt.plot(dists, tp_weights_scan[:, i], label=f'Learnable Radial {i}')
# Add title, labels, and legend
plt.title(f"First {num_basis_to_print} MACE learnable radial functions (untrained)")
plt.xlabel("distance / A")
plt.ylabel("Value")
plt.legend()
# Display the plot
plt.show()
Of course these functional forms will change after training.
3. Product¶
The key operation of MACE is the efficient construction of higher order features from the \({A}_{i}^{(t)}\)-features (the output of the interaction). This is achieved by first forming tensor products of the features, and then symmetrising, as shown in the figure. This operation:
is essentially doing \(A_{lm} \otimes A_{lm} \otimes ...\) and eventually getting back to something which transforms in a known way - \({B}^{(t)}_{i,\eta_{\nu} k LM}\). It happens on each node - all pooling between neighbours is done in the interction.
Like in the example above with two vectors, this product operation creates features which have angular information, but which are still invariant.
The final part of the product is to linearly mix everything together and create a new set of node features.
These node features don’t have to be invariant. Its possible to retain some level of equivariance and then use this extra information in the second layer of MACE, where the whole interaction an product is repeated.
Whether to do this is controlled by the max_L parameter to MACE (see the model config). If this is set to 0, then only invariant features are retained. If it is set to 1 (which is the case here), the new node features will have \(l=0\) and \(l=1\) pieces.
[ ]:
new_node_features = model.products[0](
node_feats=intermediate_node_features,
node_attrs=batch.node_attrs,
sc=sc,
)
print('new node feats are (num_atoms, (L+1)^2 * num_channels):', new_node_features.shape)
you should find that the array is (num_atoms, 32), since 32=8*4, where 4 is because we have \([Y_{00}, Y_{1,-1}, Y_{1,0}, Y_{1,1}]\) pieces, and 8 is because we have 8 ‘channels’.
You can check the equivariance of these features by modifying the above code to read a different config from rotated_solvent.xyz. This will be the same structure, but rotated. You should see that the first 32 elements are the same (since they are invariant) and the rest change.
4. Readout¶
Finally, we can take the new node features and create an actual energy. This is done by passing the node features through a readout.
In an \(S\)-layer MACE, the readout from the features at layer \(s\) is:
- :nbsphinx-math:`begin{equation*}
mathcal{R}^{(s)} left( boldsymbol{h}_i^{(s)} right) = begin{cases}
sum_{k}W^{(s)}_{k}h^{(s)}_{i,k00} & text{if} ;; 1 < s < S \[13pt] {rm MLP} left( left{ h^{(s)}_{i,k00} right}_k right) &text{if} ;; s = S
end{cases}
end{equation*}`
In our example case this maps the 32 dimensional \(h^{(1)}_{i,k00}\), the invariant part os the node features after the first interaction to the first term in the aotmic site energy:
[ ]:
print('first readout =', model.readouts[0], '\n')
energy_layer_1 = model.readouts[0](new_node_features)
print('energy_layer_1:', energy_layer_1.shape)
print(energy_layer_1)
And we have made an energy for each node!
5. Repeat¶
The Interaction, product and readout are repeated twice, and all the atomic energy contributions are summed up to get the total energy.
Interaction Block in more detail¶
At the second layer, the interaction block has a much harder task. This is because the features at the end of the first MACE layer may not be scalar, but may have an \((l,m)\) index pair.
In general, the equations for layer \(s\) are:
In this case, the learnable radial functions have a more complicated funciton.
These learnable functions are then used as weights in the operation that follows, which does a product between the \(j\rightarrow i\) edge and the initial features of node \(j\). You can see the detail in the equations above if you are interested.
Because the learnable functions are used as weights in the following conv_tp operation, the output shape is just the number of weights required by that block, and they are all invariants.
Task¶
If you really want to understand whats going on, try to work out what the output shape of the radial MLP in the second layer should be. You can access the block using some of the code snippets below:
[ ]:
# visulaise what the radial MLP does
dists = torch.tensor(np.linspace(0.1, cutoff, 100), dtype=torch.get_default_dtype()).unsqueeze(-1)
# first do radial embedding again
edge_feats_scan = model.radial_embedding(dists, batch["node_attrs"], batch["edge_index"], model.atomic_numbers)
# put the edge feats into the radial MLP
### model.interactions[1] for the second layer!!!!
# conv_tp_weights is the name for the radial MLP...
tp_weights_scan = model.interactions[1].conv_tp_weights(edge_feats_scan).detach().numpy()
print('the output of the radial MLP is (num_dists, num_weights):', tp_weights_scan.shape)
# plot the outputs if you want
num_basis_to_print = 5
for i in range(num_basis_to_print):
plt.plot(dists, tp_weights_scan[:, i], label=f'Learnable Radial {i}')
# Add title, labels, and legend
plt.title(f"First {num_basis_to_print} MACE learnable radial functions (untrained)")
plt.xlabel("distance / A")
plt.ylabel("Value")
plt.legend()
# Display the plot
plt.show()